









Novo teste mede se a inteligência artificial sabe raciocinar de verdade
Mais conceituado teste para aferir a capacidade das IAs, o ARC-AGI lança uma nova versão para verificar se os modelos conseguem raciocinar sobre problemas novos, e não apenas recordar padrões

O influente pesquisador de IA François Chollet há muito sustenta que o setor mede inteligência de forma equivocada, e que benchmarks populares acabam premiando a capacidade dos modelos de memorizar enormes volumes de dados, em vez de navegar situações inéditas e aprender novas habilidades.
Mas só recentemente, com a ascensão dos agentes autônomos de IA, as empresas começaram a levar essa crítica a sério.
Esta semana, a Fundação Prêmio ARC, criada por Chollet em parceria com Mike Knoop, cofundador da Zapier, lançou uma nova e mais difícil versão de seu benchmark.
O teste, chamado ARC-AGI-3, pode oferecer a medição mais clara até agora de quão próximos os agentes de IA atuais estão da inteligência em nível humano. Ele reúne mais de mil cenários simples, no estilo de videogames, projetados para avaliar raciocínio em tempo real, e não a simples recuperação de memória.
“Você sempre pode adquirir habilidade por meio da memorização, basicamente armazenando uma tabela de consulta com tudo o que precisa fazer”, diz Chollet. “Inteligência é a eficiência com que você consegue dar sentido a coisas novas, a tarefas que nunca viu antes.”
Sem receber instruções, o agente precisa construir uma compreensão do ambiente do jogo e de suas regras e depois aplicar esse conhecimento para elaborar uma estratégia em múltiplas etapas até alcançar um objetivo final.
Agentes que atingem esses objetivos com menos etapas, e de forma mais eficiente, recebem pontuações mais altas e seus criadores podem levar parte ou a totalidade de um prêmio de US$ 1 milhão.
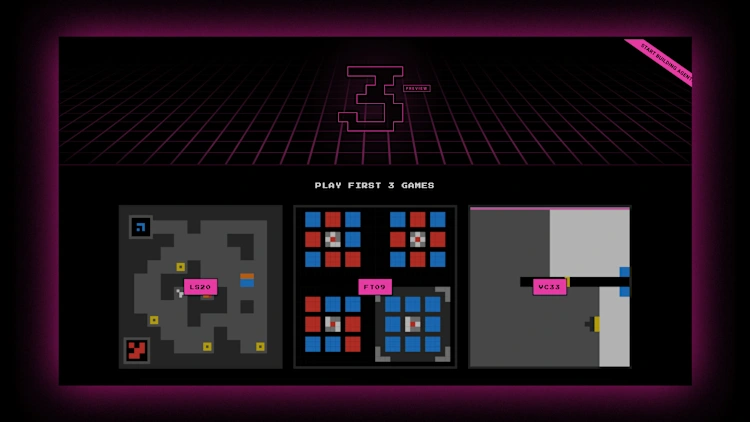
Assim como nos benchmarks ARC anteriores, humanos conseguem navegar pelas tarefas com relativa facilidade, enquanto muitos sistemas de IA ainda enfrentam dificuldades. Uma pontuação elevada no ARC-AGI-3 também pode servir como evidência de inteligência artificial geral (IAG).
Para realizar “a maior parte do trabalho com valor econômico” hoje feito por humanos, como exige uma definição comum de IAG, agentes de IA vão ter que raciocinar em situações desconhecidas, em ambientes igualmente novos.
Também terão que formar abstrações a partir de experiências passadas e aplicá-las a problemas inéditos, para os quais não foram treinados explicitamente.
NO INÍCIO ERA FÁCIL (SÓ QUE NÃO)
Quando o primeiro teste ARC foi lançado, em 2019, a arquitetura transformer por trás dos chatbots atuais tinha apenas dois anos e os modelos ainda estavam começando a gerar respostas coerentes a prompts. Como ainda não conseguiam raciocinar em tempo real, não resolviam quase nenhum dos problemas do ARC, o que limitou a adoção do benchmark.
François Chollet identificou um problema fundamental na forma como a indústria avaliava progresso. Sistemas capazes de lidar com tarefas descritas como de “nível de doutorado” falhavam em testes simples.
O teste pode oferecer a medição mais clara até agora de quão próximos os agentes de IA estão da inteligência humana.
“Quando os sistemas de IA mais avançados ficam travados, mas uma criança consegue resolver, isso é um alerta vermelho enorme de que estamos deixando algo passar, de que algo realmente importante está errado”, diz.
Os primeiros resultados do ARC-AGI-1 também apontaram para um problema mais profundo na estratégia da indústria para melhorar a IA.
“Acho que o ARC é o benchmark invicto mais importante do mundo porque é a única evidência realmente clara que contradiz a narrativa de escala que era quase dogmática no Vale do Silício em 2023 e 2024”, afirma Knoop.
Leia mais: Será que a IA vai mudar o paradigma de “homo sapiens” para “homo sentient”?
Na época, os laboratórios de IA estavam confiantes de que ampliar continuamente modelos, dados de treinamento e poder computacional levaria a ganhos de inteligência e, eventualmente, à IAG.
Mas esses sistemas permaneciam estáticos no momento da inferência (ou seja, durante a interação com o usuário) e dependiam apenas dos pesos pré-treinados para gerar respostas.
DA ESCALA AO RACIOCÍNIO
Isso começou a mudar em 2024, quando os laboratórios passaram a focar em agentes autônomos e no trabalho real que poderiam executar. “Os modelos de deep learning chegaram a um ponto em que acumularam tanto conhecimento que se tornou possível construir uma camada de raciocínio por cima deles”, diz Chollet.
Uma virada estava em curso. Novos modelos de raciocínio, como o o1 da OpenAI (lançado em setembro de 2024 como prévia de pesquisa) conseguiam decompor tarefas complexas em partes menores e avaliar múltiplos caminhos até a solução.

“Foi a primeira tentativa real de resolver o problema da inteligência fluida, que faltava no paradigma do deep learning”, afirma. Pesquisadores passaram a dar mais atenção ao ARC justamente por ele capturar essa capacidade.
“O ARC se tornou um ponto de referência de altíssimo sinal”, diz. O modelo o1 melhorou os resultados anteriores, alcançando 21% no ARC-AGI-1, contra 9% do GPT-4o, seu antecessor.
Mas foi apenas com o modelo o3 da OpenAI, lançado em janeiro de 2025, que as novas capacidades de raciocínio impactaram consideravelmente os resultados. O modelo atingiu entre 75% e 87%, dependendo da quantidade de computação utilizada, aproximando-se do desempenho humano.
Esses avanços sugeriram que o benchmark ARC poderia em breve saturar. À medida que mais modelos começaram a pontuar alto, surgiram dúvidas: esses resultados refletem raciocínio de verdade ou otimização específica para o teste?
Leia mais: Quando a IA dorme: novo modelo usa “descanso” para pensar e se aperfeiçoar
Os laboratórios já vinham usando atalhos de engenharia e sistemas especializados para melhorar o desempenho. Em maio de 2025, a Fundação Prêmio ARC lançou o ARC-AGI-2 para tornar o teste mais resistente a essas táticas.
O modelo o3, que havia alcançado cerca de 87% no ARC-AGI-1, caiu inicialmente para apenas 3% a 4% no ARC-AGI-2.
EVOLUÇÃO OU "BENCHMAXXING"?
Os laboratórios continuaram encontrando maneiras de melhorar seus resultados no ARC. Chollet acredita que a OpenAI gastou “dezenas de milhões” em computação em 2025 para treinar modelos especificamente para o ARC-AGI-2, usando exemplos públicos de testes do ARC para gerar dados adicionais de treinamento.
“No fim das contas, isso equivale a uma espécie de força bruta antecipada, tentando prever todas as tarefas possíveis com antecedência”, diz.
Ainda assim, a estratégia funcionou: as melhores pontuações subiram para 40% - 50% até dezembro de 2025, segundo Knoop. “Espero que o mesmo aconteça com o ARC-3, mas será mais difícil – e mais caro”, afirma Chollet.
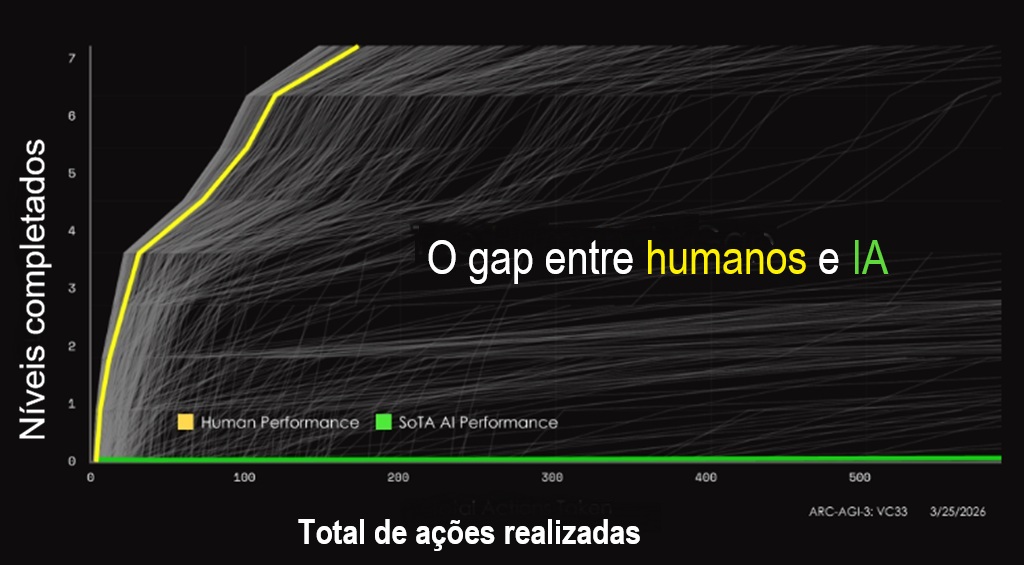
O ARC-AGI-3 chega em um momento decisivo, no qual empresas e investidores apostam trilhões de dólares que agentes de IA vão assumir grande parte do trabalho intelectual.
Os modelos estão evoluindo rapidamente, mas ainda podem carecer da intuição necessária para lidar com a complexidade e a incerteza do mundo real. Sem isso, a autonomia plena pode não se concretizar.
A própria OpenAI reconhece essa lacuna. “O ritmo de progresso da IA tem sido incrível, mas ainda há aspectos importantes em que ela fica aquém da inteligência humana”, afirmou o cientista de pesquisa Noam Brown, em comunicado à Fast Company.
O ARC-AGI-3 reúne mais de mil cenários simples projetados para avaliar raciocínio em tempo real.
“Um dos mais claros é a capacidade de se adaptar de forma eficiente a contextos inéditos, exatamente o que o ARC-AGI-3 busca testar. Benchmarks como esse ajudam a mostrar se os modelos estão se tornando mais gerais ou apenas melhores em domínios onde já se destacam”, complementou.
Provavelmente, os agentes terão um período inicial em que trabalhadores humanos vão treiná-los e corrigi-los. Depois disso, precisarão conquistar confiança e ampliar suas responsabilidades. Se falharem, empresas podem hesitar em adotá-los em larga escala.
Os agentes atuais são bons o suficiente para conquistar essa confiança? Se não, como saberemos quando forem? O ARC-AGI-3 pode ajudar a responder essas perguntas.
Leia mais: A virada dos agentes de IA: o que mudou em 2025 e o que esperar de 2026
Ao longo de 2026, os laboratórios de IA devem concentrar esforços para elevar o desempenho de seus modelos nesse novo benchmark. Nesse processo, podem acabar mais focados em desenvolver as qualidades e capacidades necessárias para que agentes realmente funcionem no mundo aqui fora.






