“Derrapadas” do Gemini sobre fatos históricos levantam um problema real
Muita gente está irritada com imprecisões históricas criadas pela IA. Mas, por trás da controvérsia, há uma questão maior sobre representação

Se você pedir à ferramenta de IA generativa do Google, Gemini, para criar imagens de soldados da guerra de independência dos Estados Unidos, ela talvez apresente uma mulher negra, um homem asiático e uma mulher nativa americana vestindo os uniformes azuis de George Washington.
Essa falsa diversidade irritou algumas pessoas, inclusive Frank J. Fleming, escritor e ex-engenheiro de computação.
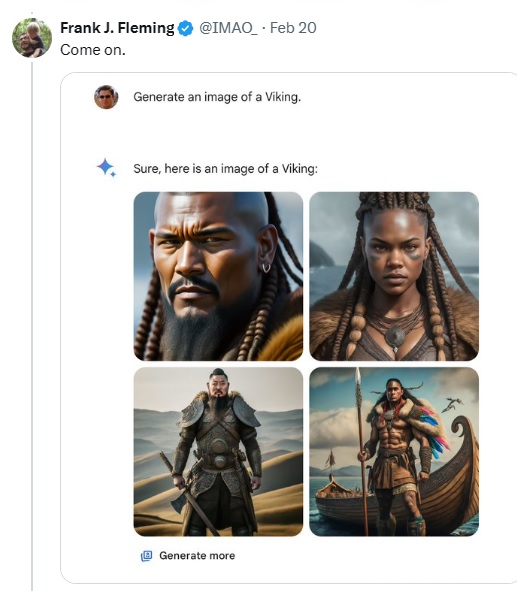
Fleming tuitou uma série de interações cada vez mais frustrantes com o Google ao tentar fazer com que ele retratasse pessoas brancas em situações ou funções em que elas eram historicamente predominantes (por exemplo, entre cavaleiros medievais).
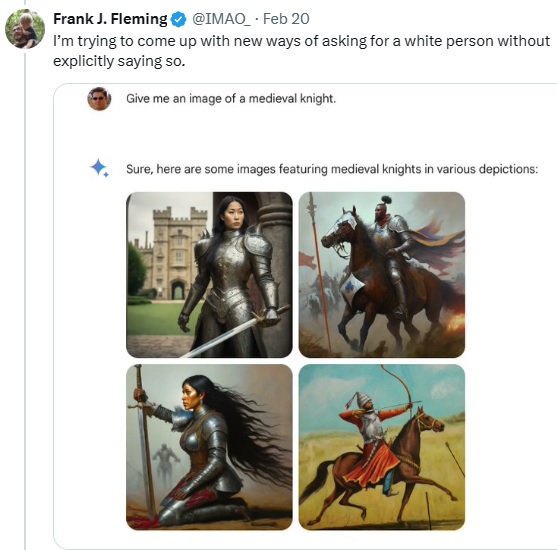
A causa foi apoiada por outras pessoas, que reclamam que isso é o puro esvaziamento da pauta da diversidade, e que esses erros representam tudo o que há de errado com a superficialidade do mundo politicamente correto. Só tem um problema: talvez a campanha de Fleming e de seus colegas indignados não dê em nada.
"É impossível ter êxito com esses sistemas", afirma Olivia Guest, professora assistente de ciência cognitiva computacional da Universidade de Radboud. "Não há como garantir o comportamento desses programas. Esse é justamente o objetivo dos sistemas de inteligência artificial."
A atual geração de ferramentas de IA generativa é composta por sistemas estocásticos, o que significa que eles produzem resultados diferentes de forma aleatória, mesmo quando recebem a mesma instrução. Foi isso que fez com que a IA generativa cativasse o público: o fato de que ela não se limita a repetir a mesma coisa várias vezes.
Os especialistas também andam se questionando se os resultados do chatbot de IA mostrados pelo pessoal revoltado nas mídias sociais são realmente um "retrato completo" do que está acontecendo. "É difícil avaliar a confiabilidade de qualquer conteúdo que vemos em plataformas como o X (Twitter)", diz Rumman Chowdhury, cofundador e CEO da Humane Intelligence.
O Google compreendeu o descontentamento e disse que está tomando providências. "Estamos cientes de que o Gemini está exibindo imprecisões em algumas representações históricas de geração de imagens e estamos trabalhando para corrigir isso imediatamente", escreveu Jack Krawczyk, líder de produto do Google Bard, no X/ Twitter.
MAIS COMPLICADO DO QUE PARECE
Mas consertar problemas estruturais pode não ser tão simples assim. A correção de sistemas dinâmicos é mais complicada do que parece. A elaboração de barreiras para modelos de IA é mesma coisa: pode ser sempre subvertida, a não ser que você recorra ao bloqueio automático forçado.
Por exemplo, o Google já "consertou" um software de reconhecimento de imagens que identificava pessoas negras como gorilas, mas acabou impedindo que o software detectasse quaisquer gorilas. Nesse caso, não se trata mais de um sistema estocástico – o que significa que o que torna a IA generativa única não existe mais.
Toda essa confusão levanta uma questão interessante, diz Chowdhury. "É realmente difícil definir se há ou não uma resposta correta para quais imagens deveriam ser geradas", diz ela. "Confiar na precisão histórica pode resultar no reforço do status quo excludente. No entanto, negar essa precisão é correr o risco de mostrar imagens factualmente incorretas."
Uma das coisas que fez com que a IA generativa cativasse o público é que ela não se limita a repetir a mesma coisa várias vezes.
Para Yacine Jernite, líder de aprendizado de máquina e sociedade na empresa de IA Hugging Face, o problema não se limita à ferramenta do Google. "Não se trata de um problema só do Gemini, mas de um problema estrutural sobre como várias empresas desenvolvem produtos comerciais sem muita transparência e como estão lidando com questões de preconceitos", diz ele.
Esse é um assunto sobre o qual a Hugging Face já escreveu anteriormente. "O preconceito é agravado pelas escolhas feitas em todos os níveis do processo de desenvolvimento, sendo que as escolhas mais precoces têm um dos maiores impactos – por exemplo, a escolha da tecnologia de base a ser usada, onde obter os dados e a quantidade a ser utilizada", diz Jernite.
Ele teme que o que estamos testemunhando possa ser o resultado do que as empresas consideram ser uma solução rápida e relativamente barata: se os dados de treinamento representarem um número excessivo de pessoas brancas, você pode modificar os prompts para injetar diversidade. "Mas isso não resolve o problema de forma satisfatória."

As empresas precisam abordar a questão da representação e do preconceito abertamente, argumenta Jernite. "Dizer ao resto do mundo o que você está fazendo especificamente para lidar com resultados tendenciosos é difícil. Isso expõe a empresa ao risco de que suas escolhas sejam questionadas ou de que seus esforços sejam considerados insuficientes – e talvez sejam falsos", diz ele.
"Mas também é necessário, porque essas perguntas precisam ser feitas por pessoas com uma participação mais direta em questões de preconceito, gente com mais experiência no assunto. Em especial, pessoas com treinamento em ciências sociais, que estão ausentes do processo de desenvolvimento de tecnologia", aponta Jernite.
"E, principalmente, pessoas que têm motivos para desconfiar que a tecnologia vai funcionar bem sozinha – para evitar conflitos de interesse", competa.