









Na guerra silenciosa entre mídia e IA, um dos lados não está jogando limpo
Novos navegadores com IA conseguem burlar barreiras e reacendem debates sobre propriedade, direitos e responsabilidade digital

Se você trabalha publicando conteúdo na internet, lidar com a inteligência artificial tem sido um desafio. Ignorá-la não é uma opção: grandes modelos de linguagem (LLMs) e mecanismos de busca com IA já estão aí, consomem seu conteúdo e o resumem para seus usuários, reduzindo drasticamente o valioso tráfego do seu site. Há dados de sobra confirmando isso.
Criar uma estratégia de conteúdo que leve em conta essa nova realidade já é, por si só, uma tarefa complexa. É preciso decidir que conteúdos expor aos sistemas de IA, o que bloquear deles e como cada uma dessas decisões pode servir ao seu negócio.
Isso já seria difícil mesmo se houvesse regras claras seguidas por todos. Mas estamos longe disso no mundo da IA. E, mesmo considerando esse cenário nebuloso, dois relatórios recentes sugerem que os dois lados estão ainda mais distantes do que parece.
- O dilema dos publishers: bots de IA estão confundindo o tráfego humano na web
- O fim da era do clique? Resumos de IA são o novo campo de batalha da mídia
- Bye bye, Google: mídia investe em novas estratégias de distribuição de conteúdo
- Mídia tem desafio de restaurar a confiança e a conexão com o público, diz Stephanie Mehta
O Common Crawl é um vasto repositório de dados da internet usado para treinar muitos sistemas de IA. Ele foi parte fundamental do GPT-3.5, modelo que alimentava o ChatGPT quando foi lançado ao mundo em 2022, e serve de base para vários outros LLMs.
Nos últimos três anos, porém, a questão dos direitos autorais e do uso de dados de treinamento tornou-se uma grande fonte de controvérsia. Diversos veículos solicitaram que o Common Crawl removesse seus conteúdos do arquivo para evitar que modelos fossem treinados sobre eles.
Um relatório da revista “The Atlantic” sugere que o Common Crawl não atendeu aos pedidos, mantendo o conteúdo, mas deixando-o invisível na ferramenta de busca, o que significa que qualquer verificação manual não daria em nada.
Criar uma estratégia de conteúdo que leve em conta a busca por IA já é, por si só, uma tarefa complexa.
O diretor executivo do Common Crawl, Rich Skrenta, disse à “The Atlantic” que a organização atende às solicitações de remoção, mas também deixou clara sua visão de que qualquer coisa publicada online deveria ser considerada disponível para treinar LLMs. “Você não deveria ter colocado seu conteúdo na internet se não queria que ele estivesse na internet”, afirmou.
Separadamente, a "Columbia Journalism Review" analisou como os novos navegadores com IA – o Comet, da Perplexity, e o ChatGPT Atlas, da OpenAI – lidam com pedidos de acesso a conteúdos protegidos por paywall.
O relatório afirma que, ao serem solicitados a recuperar um artigo exclusivo para assinantes da "MIT Technology Review", ambos os navegadores atenderam ao pedido, embora os chatbots tradicionais dessas empresas se recusassem a fazê-lo justamente por se tratar de conteúdo protegido.

Os detalhes de cada caso são importantes, mas ambos evidenciam o abismo entre as perspectivas da mídia e da indústria de tecnologia. O lado da tecnologia tende sempre ao acesso irrestrito – se a informação é digital e localizável na internet, sistemas de IA vão agir para consegui-la por qualquer meio necessário.
Os publishers, por outro lado, defendem que seu conteúdo continua pertencendo a eles, independentemente de onde e como é publicado, e que eles devem manter controle sobre quem pode acessá-lo e como ele será utilizado.
A DIFERENÇA ENTRE USUÁRIOS HUMANOS E AGENTES DE IA
O caso do Common Crawl expõe uma contradição importante em um dos principais argumentos do setor de tecnologia: a ideia de que qualquer peça individual de conteúdo não tem relevância significativa no treinamento de um LLM e que modelos poderiam facilmente prescindir dela.
Mas isso é difícil de conciliar com as ações do Common Crawl, que aparentemente assume o risco de enfrentar processos caros ao não excluir dados de publicações que solicitaram a remoção – entre elas, "The New York Times", Reuters e "The Washington Post". Quando se trata de dados de treinamento, algumas fontes são claramente mais valiosas do que outras.
Os navegadores que contornam paywalls expõem outro pressuposto equivocado do lado da IA: o de que comportamentos aceitáveis em nível individual também deveriam ser permitidos em escala. O argumento mais comum baseado nessa lógica compara o aprendizado da IA ao que seres humanos fazem naturalmente ao ler e assimilar informações.
Se o conteúdo não fosse tão valioso, não haveria tanto esforço para encontrá-lo e consumi-lo.
Mas mudanças de escala criam mudanças de categoria. Considere como paywalls normalmente funcionam: muitos são deliberadamente porosos, permitindo um número limitado de artigos gratuitos por dia, semana ou mês. Uma vez esgotado esse limite, há o velho truque da janela anônima.
Além disso, alguns paywalls carregam todo o texto da página antes de ocultá-lo com uma sobreposição. Às vezes, ao clicar rapidamente em “parar carregamento”, é possível visualizar o texto antes que o bloqueio apareça. Em um nível acima, é possível usar as ferramentas de desenvolvedor do navegador para simplesmente remover os elementos do paywall.
Internautas experientes conhecem todos esses truques, mas eles representam uma minoria dos usuários. Quem com certeza conhece esses métodos (e muitos outros) são os modelos de inteligência artificial.
Agentes de navegação como os do Comet e do Atlas funcionam como os usuários mais experientes possíveis e concedem esses poderes a qualquer pessoa que solicite informações.
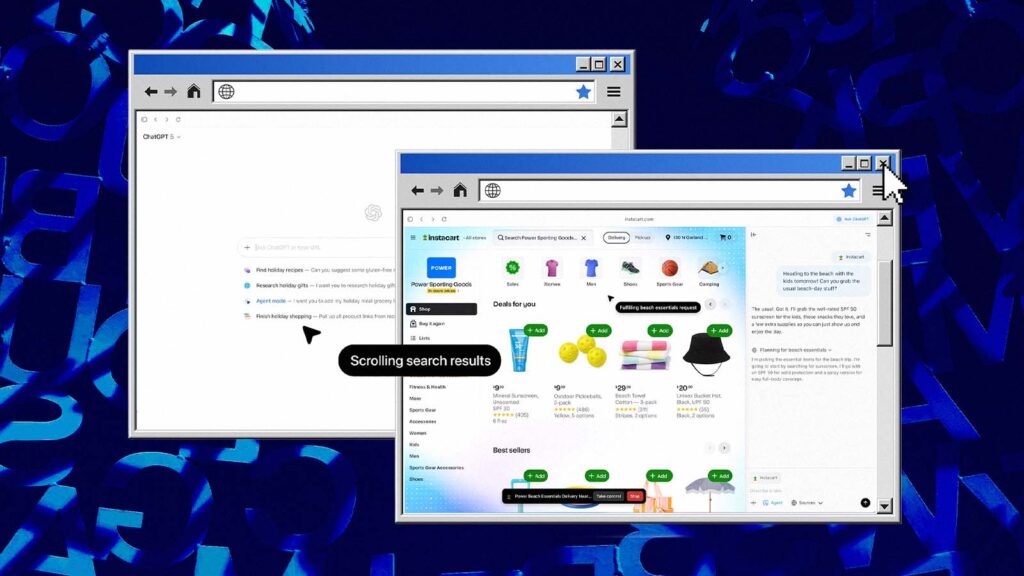
Assim, uma prática antes restrita se torna acessível em escala e paywalls se tornam invisíveis para qualquer pessoa usando um navegador com IA. Uma possível defesa seria a adoção de paywalls do lado do servidor, que entregam o conteúdo apenas após verificação de login.
Ainda assim, o que o navegador faz com os dados depois que a IA os acessa é outra questão. A OpenAI afirma que não vai treinar seus modelos com páginas acessadas pelo agente do Atlas – e, de fato, esse é o comportamento esperado de agentes desse tipo – embora admita que vai armazenar as páginas como memória do usuário.
Isso pode soar inofensivo, mas, considerando o histórico do Common Crawl, devemos realmente aceitar a palavra das empresas de tecnologia?
TRANSFORMANDO CONFLITO EM ESTRATÉGIA
Qual é a saída para o setor de mídia além de investir em paywalls do lado do servidor? A boa notícia é que seu conteúdo é mais valioso do que sugeriram até agora. Se não fosse, não haveria tanto esforço para encontrá-lo, consumi-lo e alegar que deveria ser “livre”.
A má notícia é que manter o controle sobre esse conteúdo será muito mais difícil do que parecia.
Quem com certeza conhece os truques para driblar paywalls são os modelos de IA.
Entender e gerenciar como a IA utiliza seus textos – seja para treinamento, resumos ou agentes – é um trabalho complexo, que vai muito além de técnicas e códigos. É preciso compreender também a mentalidade do outro lado.
Transformar tudo isso em estratégia real significa decidir quando lutar pelo acesso, quando permitir e quando exigir compensação. Considerando o quão volátil é o campo da IA, isso nunca será simples.
Mas se a postura agressiva, constante e abrangente das empresas de IA por mais acesso revela algo, é o quanto elas valorizam o conteúdo produzido pela mídia. É bom ser necessário, mas o sucesso vai depender de transformar essa necessidade em poder de negociação.








