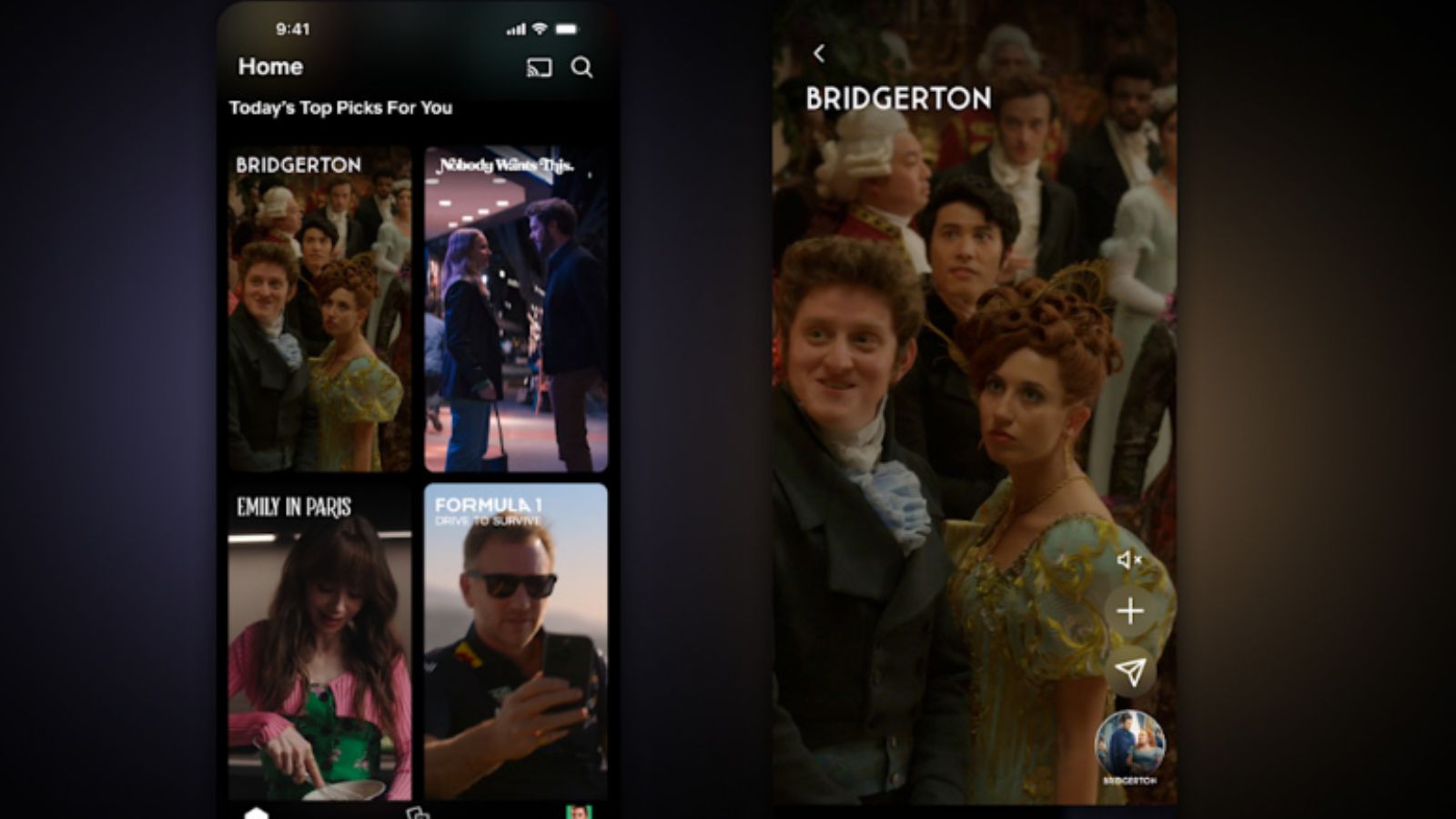





Geradores de imagens por IA têm um sério problema de representatividade
Novo estudo mostra que imagens de objetos comuns geradas por ferramentas de IA tendem a refletir padrões americanizados

Embora os Estados Unidos representem menos de 5% da população mundial e apenas 17% do mundo fale inglês, ao inserir palavras comuns, como “casa”, em geradores de imagens de IA (como DALL-E ou Stable Diffusion), os resultados frequentemente refletem a cultura norte-americana.
Isso é um problema, como mostra um novo artigo acadêmico apresentado recentemente na Conferência Internacional IEEE/CVF sobre Visão Computacional, em Paris.
Danish Pruthi e seus colegas do Instituto Indiano de Ciência em Bangalore analisaram os resultados de dois dos geradores de imagens mais populares do mundo e pediram a pessoas de 27 países que avaliassem o quão bem eles representavam os ambientes em que vivem.
Se você pedir ao DALL-E ou ao Stable Diffusion para criar uma imagem de uma bandeira, é provável que ela contenha listras e estrelas.
Os participantes receberam imagens de casas, bandeiras, casamentos, cidades, entre outros temas, e depois foram convidados a avaliar cada uma. Fora dos Estados Unidos e da Índia, a maioria das pessoas sentiu que as ferramentas de IA geravam imagens que não refletiam sua experiência de vida.
Esse sentimento é compreensível. Se você pedir ao DALL-E ou ao Stable Diffusion para criar uma imagem de uma bandeira, é provável que ela contenha listras e estrelas – o que não faz sentido para pessoas na Eslovênia ou na África do Sul, dois dos países onde a pesquisa foi realizada.
Os resultados confirmaram a hipótese dos autores. “Era algo que nos incomodava, o fato de muitos desses modelos assumirem um contexto geográfico específico”, explica Pruthi, um dos coautores do estudo. “Queríamos entender qual é o grupo demográfico padrão para quem essa tecnologia é voltada.”
DADOS USADOS NO TREINAMENTO SÃO A CHAVE
Apesar de escolherem itens ou conceitos deliberadamente universais, como casamento e casa, Pruthi ficou surpreso com a ausência de representatividade, a menos que as ferramentas fossem explicitamente instruídas a retratar algo de um país específico.
Quando solicitadas a gerar a imagem de uma casa indiana ou alemã, a precisão aumentou, subindo em média um ponto em uma escala de um a cinco, de acordo com as avaliações dos participantes.
No entanto, a melhoria foi apenas parcial, não refletindo com precisão a realidade. Em muitos países, a pontuação ficou em torno de 3,5. “Ainda há muito espaço para melhorias para tornar esses resultados mais personalizados”, observa Pruthi.
Se os bancos de dados não incluírem imagens que retratem a diversidade do mundo, a representatividade será prejudicada.
Este problema é uma questão que afeta toda a inteligência artificial: a qualidade dos resultados do modelo depende fortemente dos dados de treinamento. E nem sempre eles são bons.
O ImageNet, um dos principais bancos de imagens usado para treinar modelos de IA, há muito tempo é criticado por usar rótulos racistas e sexistas. Se esses bancos de dados não incluírem imagens que retratem a diversidade do mundo e a forma como as pessoas vivem, a representatividade será prejudicada.
Nem a OpenAI, a empresa que criou o DALL-E, nem a Stability AI, que produz o Stable Diffusion, responderam quando procuradas.
Para os autores do estudo, é necessário garantir a diversidade nos dados de treinamento. “Essas tecnologias são tidas como transformadoras. São consideradas facilitadoras da criatividade, e se espera que muitas atividades econômicas sejam impulsionadas por elas. Mas, se é muito mais difícil para um artista na Índia utilizá-las, isso se torna um problema sério”, diz Pruthi.