








A primeira onda de inovação da IA está chegando ao fim. O que vem por aí?
Empresas fora do setor precisam ter o controle sobre os modelos de inteligência artificial

Imagine pedir dicas a um modelo de inteligência artificial sofisticado sobre como fazer a pizza perfeita e ele sugerir usar cola para ajudar o queijo a grudar. Ou vê-lo cometer erros básicos de matemática que nem mesmo um aluno do ensino fundamental faria.
Estas são algumas das limitações e peculiaridades da IA generativa e dos grandes modelos de linguagem (LLMs, na sigla em inglês). Isso acontece porque esses modelos estão ficando sem dados de treinamento de qualidade, o que faz com que atinjam um platô.
Este é um ciclo de inovação que se repete ao longo da história. Por muito tempo, uma quantidade quase imperceptível de conhecimento e habilidade se acumula em torno de uma ideia, como um gás invisível.
Então, surge uma faísca. Uma explosão de inovação ocorre, mas, com o tempo, atinge um limite. Esse padrão é chamado de “curva S”. Alguns exemplos:
- O TCP/IP: originado a partir de ideias dos anos 1960, este conjunto de protocolos viu uma aceleração significativa após a publicação de seus padrões, em 1974, e se estabilizou com a versão 4, em 1981, que ainda sustenta a internet moderna.
- A “Guerra dos Navegadores”: no final dos anos 1990, os navegadores de internet evoluíram rapidamente para plataformas interativas e programáveis. Desde então, as melhorias têm sido, em grande parte, incrementais.
- Aplicativos Móveis: o lançamento da App Store do iPhone, em 2008, estimulou uma onda de inovação. Hoje, aplicativos móveis verdadeiramente inovadores são raros.
O PLATÔ DA IA
A revolução da IA segue esta curva. Alan Turing foi um dos primeiros cientistas da computação a explorar como construir uma máquina pensante, em um artigo publicado em 1950, iniciando o acúmulo de conhecimento.
Setenta anos depois, a faísca: um artigo chamado “Attention Is All You Need” (Tudo o Que Precisamos é de Atenção) levou ao desenvolvimento do ChatGPT pela OpenAI, que imita de forma convincente a interação humana, desencadeando uma onda global de inovação baseada na tecnologia de IA generativa.
Por certo tempo, todos os lançamentos de LLMs, mesmo de outras empresas, como Anthropic, Google e Meta, ofereciam melhorias drásticas. Mas, recentemente, o progresso diminuiu. Veja o gráfico sobre o incremento da performance do principal modelo da OpenAI:
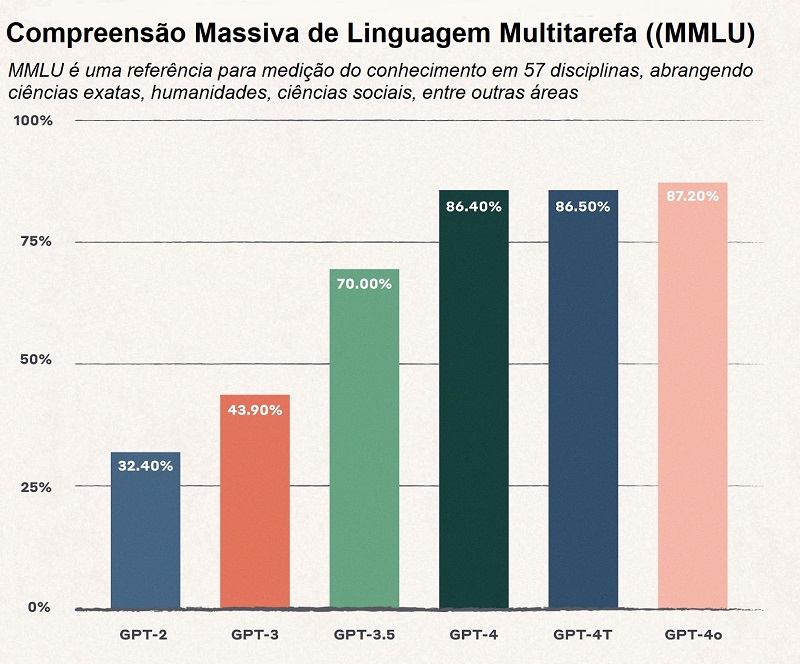
A falta de dados de treinamento de qualidade foi o que causou essa estagnação nos avanços da IA. O acesso à próxima fronteira de dados é o que ela precisa para dar o salto para a próxima curva S.
Os modelos atuais foram treinados principalmente com dados públicos disponíveis na internet, mas isso não é mais suficiente para sustentar melhorias. Para saciar sua fome de novos dados, a OpenAI, por exemplo, desenvolveu uma rede neural chamada Whisper, para transcrever um milhão de horas de vídeos do YouTube para o GPT-4.
Outros métodos novos sendo usados incluem a contratação de rotuladores humanos por meio de serviços como o ScaleAI (muitos dos quais estão sendo acusados de más condições de trabalho). No entanto, dados mostram claramente que continuar por esses caminhos leva a menos retorno financeiro.
A PRÓXIMA CURVA: DADOS EMPRESARIAIS
Acreditamos que a verdadeira inovação que permitirá à humanidade saltar para a próxima curva S são os dados produzidos nas empresas. Dados como especificações de produtos, apresentações de vendas e interações de suporte ao cliente têm uma qualidade muito superior aos dados públicos que ainda restam para fins de treinamento.
Startups que tiverem acesso e aproveitarem dados empresariais terão mais chances de desenvolver ferramentas realmente úteis para as organizações. O potencial da IA no espaço B2B é vasto e, em grande parte, inexplorado. Trabalhadores do conhecimento produzem continuamente dados empresariais a um ritmo incrível:
- Em 2020, o Zoom capturou 3,3 trilhões de minutos de reuniões (55 bilhões de horas). Isso supera os estimados 150 milhões de horas de conteúdo total do YouTube.
- O Ironclad processa mais de um bilhão de documentos por ano.
- O Slack entrega mais de um bilhão de mensagens por semana.
Comparamos a receita média por usuário dos principais aplicativos de consumo com o preço “por assento” de apps B2B selecionados. Mesmo aplicativos empresariais mais “orientados ao consumidor”, como o Notion, ainda ganham muito mais receita por usuário do que empresas de tecnologia de consumo.

UM CAMINHO INCERTO
No entanto, as empresas estão certas em ser cautelosas em relação à forma como os provedores de LLM abordam casos de uso empresarial. A OpenAI e a Anthropic afirmam que não treinam modelos com dados de assinaturas empresariais. Mas a pressão para expandir seus negócios pode forçá-las a recuar.
A Meta, por exemplo, alegava ignorar a atividade dos usuários em sites parceiros enquanto eles estavam desconectados. Mas, mesmo após US$ 725 milhões em acordos relacionados à privacidade, ela continuou coletando dados de consumidores a um ritmo absurdo.
Como pioneira em software em nuvem, a Salesforce, no início, se comprometeu a não compartilhar dados de clientes com terceiros. Mas sua atual política de privacidade diz o contrário.
É por isso que acreditamos que as próprias empresas – e não as empresas de inteligência artificial de código fechado – precisam ter o controle sobre os modelos de IA.
Assim como o “The New York Times” está lutando para proteger sua propriedade intelectual, elas devem resistir, para que seus dados proprietários não sejam roubados da mesma maneira que os dados públicos foram.
Uma versão deste artigo foi publicada pela primeira vez no blog Emergence Capital.







