IA consegue prever como novas drogas vão interagir com o corpo humano
O AlphaFold 3 pode acelerar a descoberta de novos medicamentos, melhores antibióticos e vacinas mais eficazes
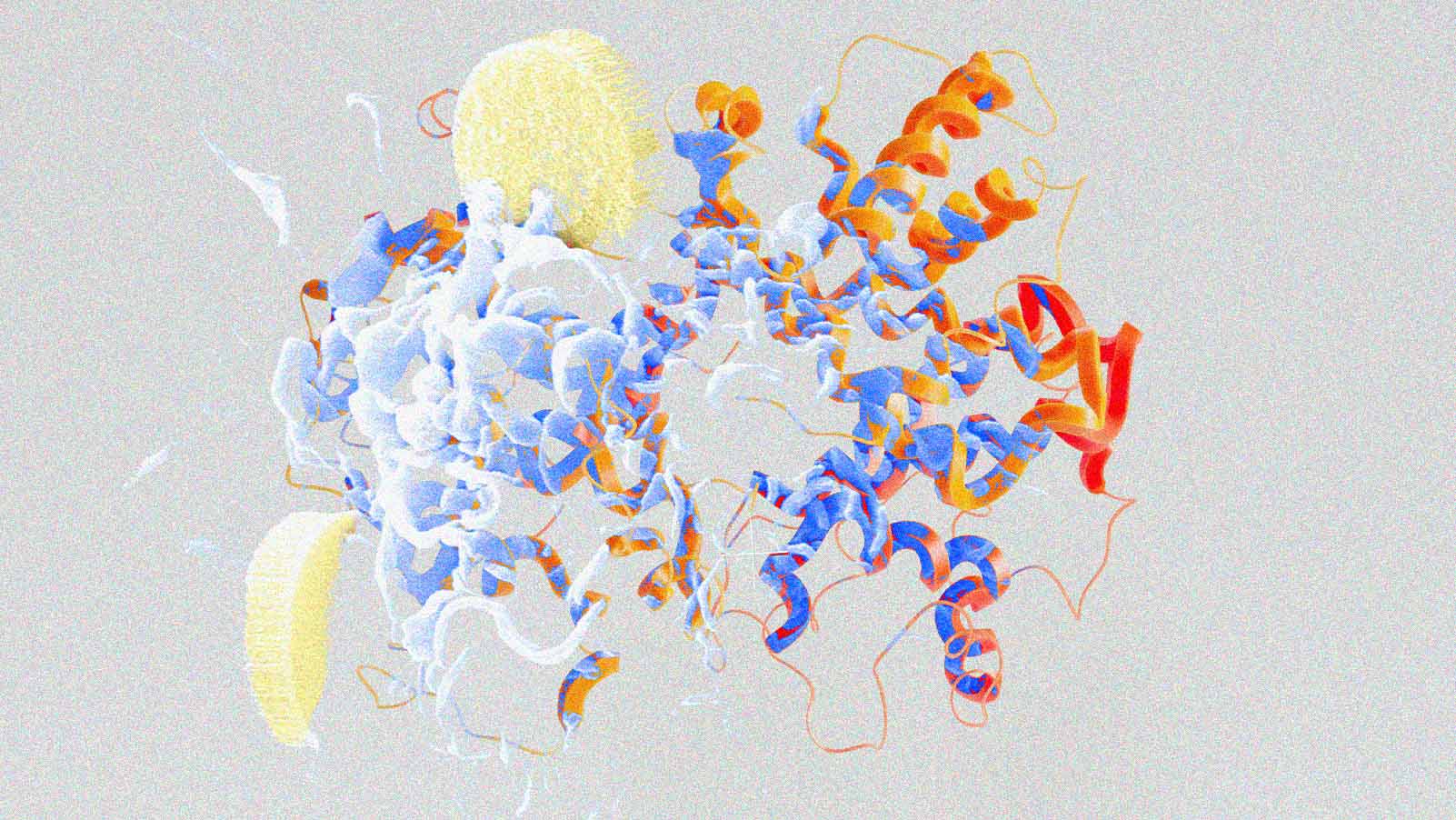
O Google DeepMind expandiu seu sistema de IA AlphaFold, que agora não apenas prevê a estrutura de proteínas, mas também como elas interagem com outras estruturas celulares, como o DNA, o RNA e pequenas moléculas usadas em medicamentos.
O novo sistema, chamado AlphaFold 3, pode simular como as proteínas “leem” nosso DNA e executam as instruções no corpo.
Desenvolvido pela DeepMind em parceria com a Isomorphic Labs, o modelo oferece aos pesquisadores uma ferramenta mais poderosa para prever como novos compostos podem reagir com certos receptores no corpo, o que pode acelerar o desenvolvimento de novos medicamentos. Esse trabalho costuma ser realizado experimentalmente em laboratório.
“Imagine que o AlphaFold lhe dá a estrutura de uma proteína de seu interesse. Com o novo modelo, podemos projetar um composto ou um ‘mensageiro químico’ que se ligará a um local específico na superfície da proteína, para prever o quão forte será essa ligação”, explica o CEO da DeepMind, Demis Hassabis.
“Este é um passo crucial se queremos desenvolver medicamentos”, afirma Hassabis. “Isso inaugura o que eu chamo de design racional de medicamentos baseado na estrutura”, acrescenta Max Jaderberg, cientista-chefe de IA da Isomorphic.
ACESSO NA NUVEM PARA PESQUISADORES
O AlphaFold 3 não leva os pesquisadores diretamente a um novo medicamento. Outros modelos de IA são necessários para prever interações com outras drogas. Além disso, todas as interações previstas precisam ser comprovadas em laboratório e, mais tarde, em ensaios clínicos em humanos. Mas a ferramenta pode fornecer aos pesquisadores insights valiosos sobre onde focar seus esforços.
Ela também pode ser usada para projetar moléculas de alimentos que sejam, por exemplo, mais resistentes à deterioração, ou para desenvolver antibióticos novos e mais eficazes, além de auxiliar no desenvolvimento inicial de novas vacinas.

Em vez de tornar o novo modelo de código aberto, a DeepMind está oferecendo um “AlphaFold Server” em nuvem, onde pesquisadores e acadêmicos podem acessar o sistema 3 e “gerar estruturas biológicas”, segundo a empresa.
Isso pode ser muito útil para cientistas que não têm experiência em bioinformática ou que não têm acesso ao poder computacional necessário para rodar o modelo. Hassabis diz que a empresa está usando o novo sistema para desenvolver medicamentos com a Isomorphic, que, por sua vez, está trabalhando com a Novartis e a Eli Lilly.
“Vimos enormes avanços em precisão em comparação com outras ferramentas e até mesmo com o AlphaFold 2 nos diferentes tipos de previsões que fazemos”, observa John Jumper, líder da equipe do AlphaFold. Segundo ele, ao prever como as proteínas se ligam ao DNA, por exemplo, o AlphaFold 3 foi 65% preciso (comparado aos 28% dos modelos atuais).
ESCASSEZ DE DADOS CONFIÁVEIS
O AlphaFold 3 é um grande avanço para a bioinformática, ainda que represente apenas um dos primeiros passos em uma longa jornada para construir uma IA capaz de analisar com alta precisão o vasto universo de interações biológicas e moleculares na natureza.
Mas a DeepMind pode ter um enorme desafio pela frente. O motivo? A escassez de dados de treinamento confiáveis – o mesmo problema que grandes modelos de linguagem podem enfrentar.
todas as interações previstas pelo sistema precisam ser comprovadas em laboratório e em ensaios clínicos em humanos.
“É incrível que eles consigam fazer esses tipos de avanços apenas aprimorando o lado tecnológico da equação”, diz Anna Marie Wagner, chefe de IA da Ginkgo Bioworks.
Wagner explica que dar grandes passos na modelagem de estruturas e comportamentos biológicos requer três componentes principais: poder computacional, tecnologia (ou seja, software) e dados.
O AlphaFold é um modelo poderoso, com o poder computacional do Google por trás, mas depende da disponibilidade de conjuntos de dados de testes laboratoriais para seu treinamento.
“Precisamos gerar grandes conjuntos de dados diversos que sejam representativos para treinar o modelo”, explica Wagner. “O que me empolga é a possibilidade de combinar esses avanços com dados multimodais que permitem que esses modelos aprendam ainda mais rápido. É aí que acho que começamos a ver a verdadeira mágica.”